PRODUCT SMART UQ
データサンプリング
DOEは通常、システムから新しいデータを収集するために使用されます。多くの場合、十分なデータがすでに収集されています。多くの場合、これらのシナリオでは、収集されたデータは長期間にわたって蓄積されており、分析が単純に手に負えないほど十分なデータがあります。たとえば、フィールドコンポーネントのセンサーからのヘルスモニタリングデータは、コンポーネントの動作寿命全体にわたって継続的にライブデータをキャプチャする場合があります。SmartUQのデータサンプリングツールは、データを分割して、完全なデータセットのサブセットで構成されるスペースを埋めるDOEを模倣できます。データ収集の前に開発されたDOEとは異なり、サブサンプリングやスライスサンプリングなどのデータサンプリングは、既存の入出力データペアを取得し、設計空間を適切に表すポイントを選択します。
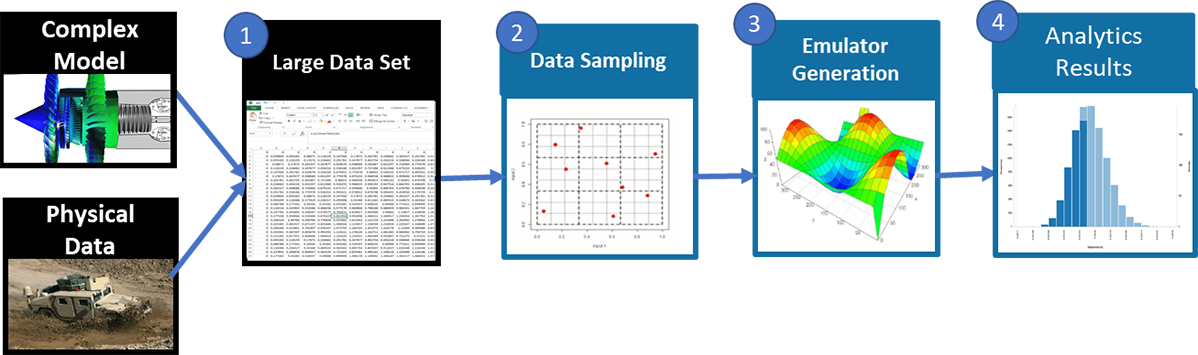
データサンプリングのワークフロー図
データサンプリングツールのワークフローは、シミュレーションや計測データから収集したデータセットが起点となります。データセットは大規模なものになる傾向があり、データセット全体を使って解析を行うのは計算負荷が高い場合があります。SmartUQのデータサンプリングツールは、データセットを、設計空間をよく表す小さなサブセットに分割することができます。
サブサンプリングアルゴリズム
スライスデザインと同様に、スライスサンプリングアルゴリズムはデータセットをグループに分割します。ただし、初期データセットはスペースを埋める設計であるとは見なされなくなりました。各スライスを使用して、エミュレーターを構築したり、モデルの検証を実行したりできます。 スライス構造によって可能になる独自のエミュレーションプロセスは、エミュレーションの分割と結合の方法です。トレーニングに使用される各スライスには独自のエミュレーターがあり、すべてのエミュレーターが1つのエミュレーターに結合されて最終結果が得られます。これにより、並列コンピューティングが可能になり、大規模なデータセットの高度な分析を実行するために必要なメモリ要件が軽減されます。
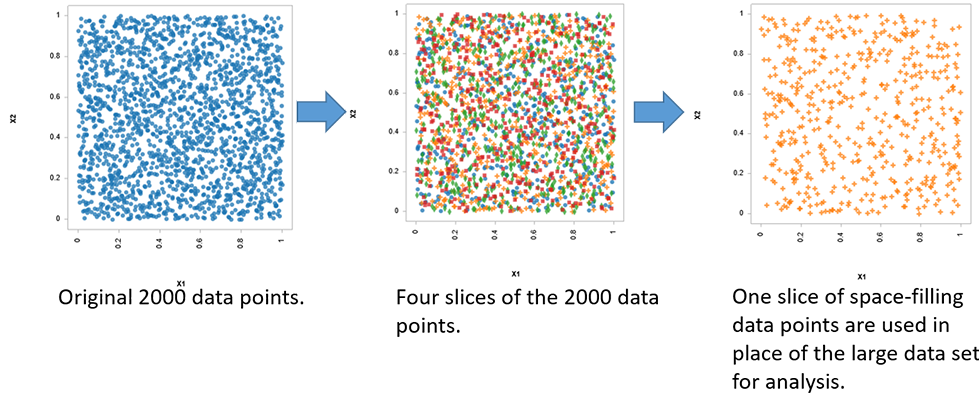
スライスサンプリングのプロセス
既存のデータセットを4つのスライスに切り分け、それぞれのスライスが空間を埋めるためのDOEを模倣しています。
スライスサンプリングアルゴリズム
サブサンプリングアルゴリズムは、既存の大きなデータセットからユーザーが指定した数のポイントをサンプリングして、元のデータセットを適切に表現します。データセットを任意に2つに分割するのとは異なり、サブサンプリングツールは、スペースを埋めるDOEを模倣するポイントを考慮し、サブサンプリングされたデータセットの潜在的なバイアスを減らします。初期データのサブセットのみを使用することにより、計算負荷が大幅に軽減され、高度な分析を正確に実行する機能がインテリジェントな選択プロセスを通じて維持されます。データのより大きな残りのサブセットを使用してモデルの検証を実行できるため、予測の精度に自信を持ちながら、シミュレーションとテストのリソースを節約できます。
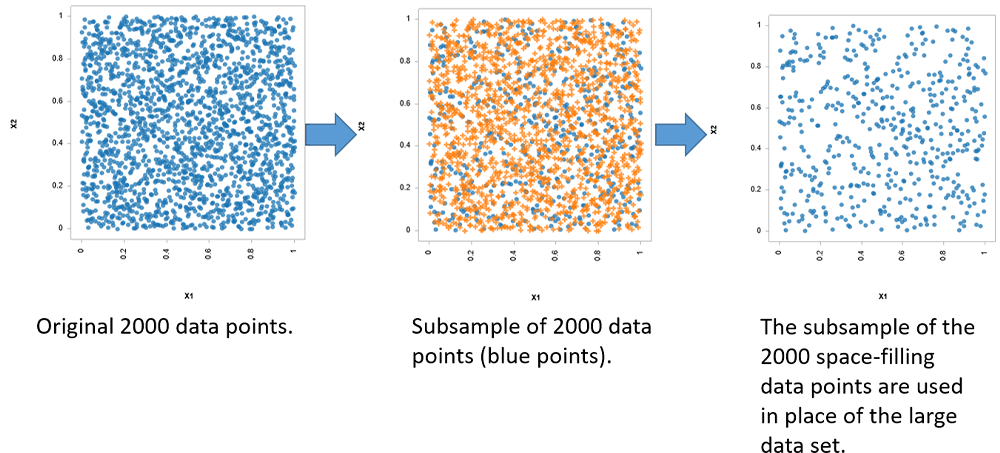
サブサンプリングプロセス
既存のデータセットをサブサンプリング(再分割)することで、空間を埋めるDOEを模倣しています。